A simple introduction on Sinkhorn distances
The Sinkhorn distance [1] was proposed in 2013, and the work was accepted in NIPS conference. The goal is to improve the optimization speed to solve the optimal transportation problem. Thus, there are several concepts. 1) transportation problem, 2) optimal transportation problem, 3) optimize it, 4) optimization speed improvement. The concept may be kind of new, but I will try to explain it step by step.
Transportation problem
Let’s imagine we have some mines, which are able to produce the iron ores. The iron ore will be used by some factories for further processing. We don’t need to know how they process the iron ore, or why they want to process that. Instead, we mainly focus on the amount. That is, each mine can produce different amounts of iron ore and each factory may also require different amount of iron ore. Let’s assume, we have 2 mines: A and B. We have 3 factories to use the iron ore: X, Y and Z. A can produce 3 iron ores while B can produce 7 iron ores. The unit could be tonnage, or kiloton. We don’t assume what it is, but only assume the unit is consistent among all the numbers. In this assumption, we can ignore the unit, and only focus on the number value. For the factories, X needs 4, Y needs 5, and Z needs 1. This is our basic setup: we have producers, which are the mines, and we have the consumers, which are the factories.
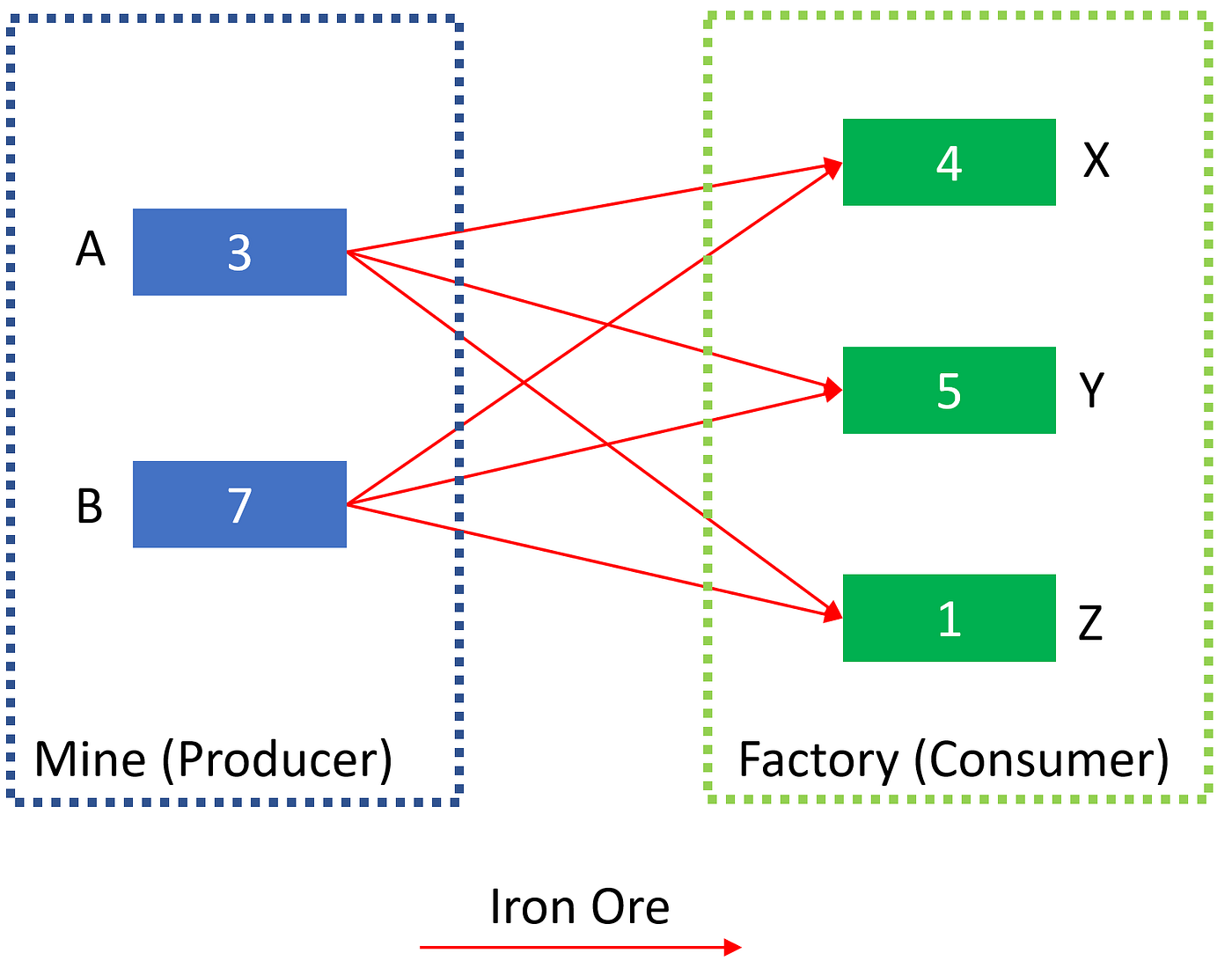
The transportation problem is to transport all those iron ore produced by the mines to the factory. We need some effort, either by train or by boat to do it. We also need to design the path. Different transportation effort could lead to different cost. Money. Although we have different transportation ways to save money, we assume the transportation cost here is fixed and only depends on what the mine is and what the factory is. For example of mine A and factory X, we have a cost value, say C(A, X). The cost is always a non-negative value, and represent the cost for a unit iron ore. That is, if we transport 1 iron ore, the cost is C; if we transport 2 iron ores, the cost will will be 2C. Now, we have the cost relationship between any mine and any factory. The rest problem is how much we should transport between each mine and each factory. Let’s say, the amount is P(i, j), where i belongs to {A, B}, and j belongs to {X, Y, Z}. The transportation amount should also be non-negative. Given any such kind of amount P(i, j), we will have a deterministic total cost, and the cost can be written as ∑P(i,j)C(i, j). We also call P(i, j) as the transportation plan. Different transportation plans will result in different total cost, and we always would like to minimize such cost to save money. Then, we arrive at our optimal transportation problem.

One observation here is that the total amount of iron ore each mine produces is equal to the amount of iron ore each factory requires. We will also only focus on this problem, and ignore the case where the producers produce more than the needed, or vice versa. This constraint is on the problem setup, rather than the unknown parameters of P(i, j). Thus, we can always check whether the problem you are studying on belongs to such transportation problem.
Another thing is that we do not care the unit. Thus, we further normalize the amount which can be produced or consumed, so that the sum is 1. Here, as shown in Fig. 2, we use r(i) to represent the amount of iron ore the producer can produce, and c(j) to represent the amount the factory needs. We normalize them, which means ∑r(i)=1 and ∑c(j)=1. After such normalization, we can interpret both r(i) and c(j) as probability distributions. Given the cost relation C, the total cost will be deterministic by the two probability distributions. That is, the total cost is a function of two distributions, which means we can use the total cost to measure the distance between two distributions to some extent. This is a good thing as we have another way to measure the distance, beyond the popular KL distance. However, the distance is not necessarily to be a metric distance unless the cost relation satisfies some condition. When we say a function is a distance, it should satisfy at least that if the two distributions are identical, the value should be 0. In this case, if all entries in C is positive, the minimal total cost won’t be 0 for sure though the distributions are identical. To make it a metric, the requirement is that 1) C(i,j) = 0 ↔ i=j, 2) C(i, j)+C(j, k) ≥ C(i, j). We don’t have to understand how to prove the correctness, but at least we know for some kinds of C, the minimal cost can be used as a distance for two distributions.
If you are familiar with the convex optimization, you can easily verify that the optimal transportation problem is a convex problem, which can be easily solved by some off-the-shelf toolbox. This is true, but the problem is that the complexity could be high especially when the dimension is large. Improving the optimization speed is the goal of this paper or sinkhorn distances.
Sinkhorn distances

Until now, we have the optimal transportation problem, which is illustrated on the left side of Fig. 3. As the paper [1] proposed, the sinkhorn distances will be defined as the optimal value of a revised optimal transportation problem, which is illustrated on the right side of Fig. 3. Here, it imposes one extra constraint to make sure that the KL divergence distance between P and rc is smaller to some pre-defined parameter. So, what is the meaning of this? First, based on the constraint, we know the transportation plan P(i, j) should also be a probability distribution. Each entry should be non-negative, and the sum of all entries is 1. Since r and c are both distributions, rc will also be a distribution. As for KL distance, if the two distribution is the same, the distance is 0. Here it means the distance between the two distances should be close, or the optimal solution of P(i,j) should be around the distribution of rc, which is pre-defined as both r and c is known.
Before going on, let’s take a look at what rc is. First of all, rc is a probability distribution because all entries’ sum will be 1. The following illustrates how the transportation plan is with rc. We can see, this plan means, for the producer, if it produces more, it should transport more; for the consumer, if it needs more, it should receive proportionally more from each producer.

Then, let’s look at the revised optimal transportation problem in Fig. 3. The extra constraint is about KL divergence, and we can expand it as follows.

Considering the constraint of ∑_i P(i, j)=c(j) and ∑_j P(i, j)=r_i. We can easily verify that the last two items in the equation has nothing to do with P(i, j). Meanwhile, all 3 items coincides with the entry definition. Thus, we can write the constraint as simple as follows.

From the equation, we can re-interpret the constraint as that the entropy of P should be as large as possible. In terms of optimization, with such constraint, the problem becomes non-convex, which is normally hard to optimize. Considering that the parameter of α also needs tuning, we can put the constraint to the objective function, with the removal of the constant variables, e.g. entropy of r and c. In this case, we will have the dual Sinkhorn distance.
Dual Sinkhorn distance

From Fig. 7, we can see the dual sinkhorn distance is the minimal cost over an updated objective function which expects to minimize the total cost and to maximize the entropy of P(i,j). It is easily to verify that the linear function and the negative of entropy function is convex function. Thus, this optimization is convex, which is good. Next, we will focus on how to optimize such problem.
Optimization
As it is convex, we can write the langrage form by introducing the coefficients of m and n.

Then, the derivative regarding P should be 0.

By taking a closer look at the solution, we know the optimal P should follow the form of multiplications over 3 matrices. The first and the last one is the diagonal matrix and the middle one relying only on λ and C, both of which are pre-defined parameters. The problem of solving u and v is accidentally studied well in Sinkhorn’s theorem. The theorem says, the solution is unique up to a multiplier. That is, if we find one solution of (u, v), all other solution has to be (u*T, v/T) with T being some propriate scalar. This is good. It means, if we find one solution, we don’t need to worry there is some other solution to satisfy this form also. Since the problem is strict convex, the optimal solution is unique, and the unique solution should satisfy this form. Consequentially, we can assert that if we find one solution of (u, v), our job is done. Sinkhorn algorithm also solves the problem elegently. That is, we can find such (u, v) by alternating updating u with a fixed v, and then updating v with a fixed u. Solving both u and v only involves some matrix calculation, which can be easily to be implemented in GPU for parallel computing. This is also good news for deep learning approach.
This is all the key idea of the sinkhorn distances. The application can be broad, as long as we can model the real problem by this producer/consumer scenarios.
[1] Sinkhorn Distances: Lightspeed Computation of Optimal Transportation Distances [arxiv]