Understanding pytorch’s autograd with grad_fn and next_functions
As we know, the gradient is automatically calculated in pytorch. The key is the property of grad_fn of the final loss function and the grad_fn’s next_functions. This blog summarizes some understanding, and please feel free to comment if anything is incorrect.
Let’s have a simple example first.
torch.manual_seed(6)
x = torch.randn(4, 4, requires_grad=True)
y = torch.randn(4, 4, requires_grad=True)
z = x * y
l = z.sum()l.backward()
print(x.grad)
print(y.grad)
The output is
tensor([[-1.4801, -1.0631, 0.3630, 0.3995],
[ 0.1457, -0.7345, -0.9873, 1.8512],
[-1.3437, 0.8535, 0.8811, -0.6522],
[ 0.5810, 0.3561, 0.0160, 0.4019]])
tensor([[-1.2113, 0.6304, -1.4713, -1.3352],
[-0.4897, 0.1317, 0.3295, 0.3264],
[-0.4806, 1.1032, 2.5485, 0.3006],
[-0.5432, -1.0841, 1.4612, -1.6279]])Here, we can have a simple workflow of the program.
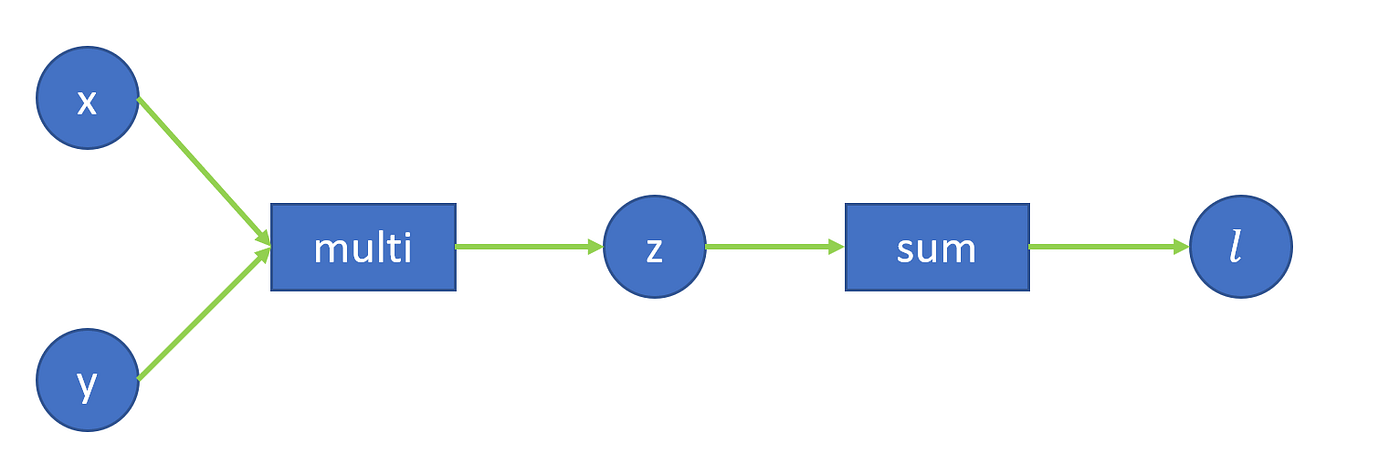
We can easily derive the gradient of x and y by l.backward(). The next part is, how to calculate such gradient by grad_fn and next_functions so that we can understand better on how autograd works.
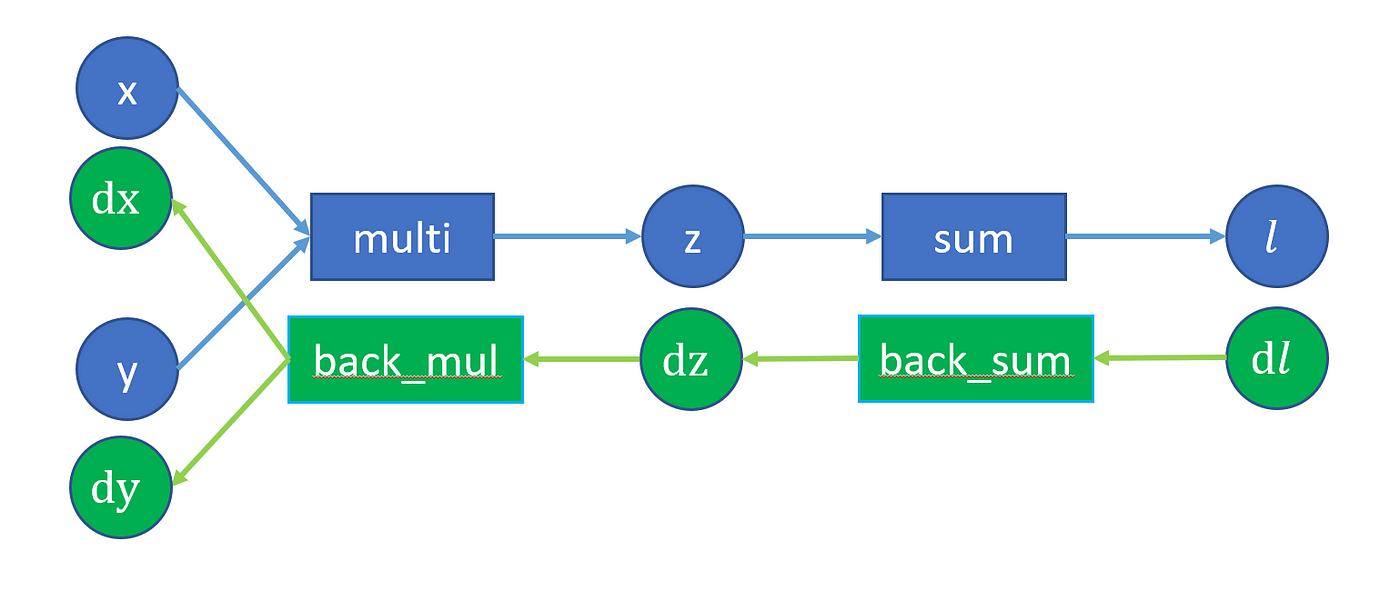
Based on the chain rule, we can imagine each variable (x, y, z, l) is associated with its gradient, and here we denote it as (dx, dy, dz, dl). As the last variable of l is the loss, the gradient is 1. Then, we can calculate the gradient of x and y by the following.
torch.manual_seed(6)
x = torch.randn(4, 4, requires_grad=True)
y = torch.randn(4, 4, requires_grad=True)
z = x * y
l = z.sum()dl = torch.tensor(1.)back_sum = l.grad_fn
dz = back_sum(dl)
back_mul = back_sum.next_functions[0][0]
dx, dy = back_mul(dz)
back_x = back_mul.next_functions[0][0]
back_x(dx)back_y = back_mul.next_functions[1][0]
back_y(dy)
print(x.grad)
print(y.grad)
The output is the same as what we got from l.backward(). Some notes are
- l.grad_fn is the backward function of how we get l, and here we assign it to back_sum.
- back_sum.next_functions returns a tuple, each element of which is also a tuple with two elements. The first is the next function we need to call, e.g. back_mul in the example. The second is the argument index of back_mul for dz. That is, dz will be the 0-th argument of back_mul if the second index is 0, which is the case.
- back_mul(dz) will return two elements, which means back_mul.next_functions will contain two elements. The first output (dx) will be used as the 0-th (back_mul.next_functions[0][1] == 0)argument of back_mul.next_functions[0][0]; while the second output (dy) will be used as the 0-th (back_mul.next_functions[1][0] == 0) argument of back_mul.next_functions[1][0].
- In the end, we can call back_x(dx) and back_y(dy) to populate the grad field of x and y, respectively.
The interesting part is the next_functions, which tells how to distribute grad_fn’s outputs. If there is N output, there will be N tuples in next_functions. Each tuple’s first element is the next function to call, and the second is the argument index of such output variable. Normally, the next function to call is different among the N tuples, but sometimes it could be the same, as shown in the following
torch.manual_seed(6)
x = torch.randn(2, requires_grad=True)
x1, x2 = x.unbind()
l = x1 + x2dl = torch.tensor(1.)
back_sum = l.grad_fndx1, dx2 = back_sum(dl)
assert len(back_sum.next_functions) == 2
assert back_sum.next_functions[0][0] == back_sum.next_functions[1][0]
assert back_sum.next_functions[0][1] == 0
assert back_sum.next_functions[1][1] == 1
back_split = back_sum.next_functions[0][0]
dx = back_split(dx1, dx2)
back_split.next_functions[0][0](dx)
print(x.grad)
useful thread: